Tag: open data
-

“What is WeGovNYC?”, presented online for NYC Open Data Week 2021
A presentation on the progress of WeGovNYC’s Databook, an open government solution that combines a data normalization pipeline with a custom interface to deliver the public a data-driven understanding of NYC’s government.
-

Going from Spreadsheets to Airtable to Apps presented online for NYC Open Data Week 2021
A methodology for building custom apps step by step: starting with a few spreadsheets, combining them together in Airtable, and then building a front-end app.
-

Buildings Apps “With Not For” presented at School of Data event in New York City on March 7th, 2020
A presention of a method for building information rich apps using spreadsheets and DIY database tools like Airtable.
-

5 Solutions the Public Advocate Should Deliver for New York City
This article was originally published on Gotham Gazette on May 8, 2019 The New York City Public Advocate is a poorly defined position that, over its 30 years of existence, has often been used to advance the political interests and status of career politicians. I’m running for Public Advocate because I want to do something very different…
-

SimCity Showed Us Brilliant Civic Tech Interfaces 30 Years Ago. We Should Build Them for Real Now
This article was originally published on Gotham Gazette on May 8, 2019 I was eight years old when I first encountered a computer game called SimCity. The general premise of the game was that you were the mayor of a virtual city, and you would use game money to create a place for communities of “Sims” to live.…
-

Breakthroughs in Open Aid Presented at National VOAD Conference, May 6th, 2019
I presented the following in Nashville, Tennessee on May 6th, 2019 PDF Download
-

New York City Shouldn’t Regulate Ride-Hailing Apps – It Should Compete With Them
This article was originally published on Gotham Gazette on November 30, 2018 Smartphones are transforming transit in cities all over the world, and city governments are struggling to figure out how to best manage the change. If the world was looking to New York City’s recently enacted legislation affecting for-hire vehicle companies, then there will be disappointment…
-
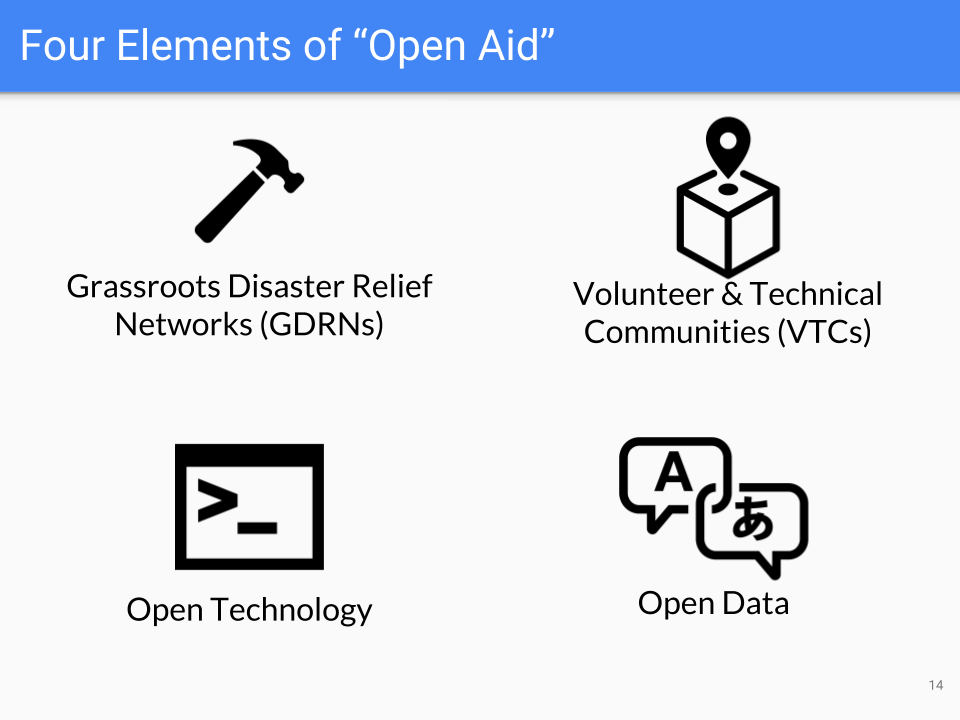
“The Open Aid Movement” Presented at NVOAD Conference May 9th, 2018
I had the honor of presenting “The Open Aid Movement” at the 2018 NVOAD conference in Providence, Rhode Island. This presentation offers an overview of the Open Aid Movement and its four components. Each component had a case study that was prepared by an expert in that specific area. The four components and slide contributors…
-
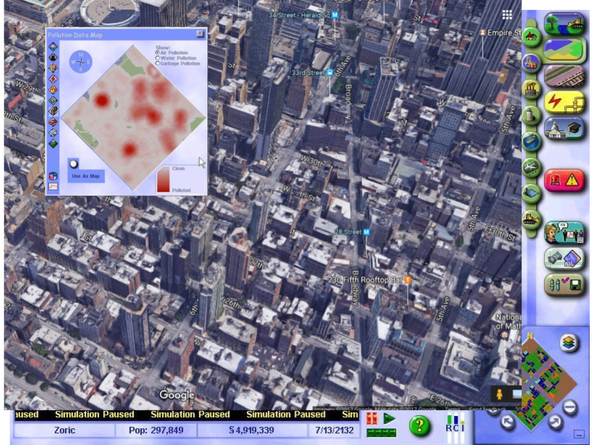
Imagining SimNYCity
I was eight years old when I first encountered a computer game called “SimCity.” The general premise of the game was that you were the mayor of a virtual city, and you would use game money to create a place for communities of “Sims” to live. First you set up basic infrastructure like roads, pipes,…
-

OpEd: Disaster Preparedness Requires a 211 System; New York City Still Doesn’t Have One
This piece was originally published on Gotham Gazette on October 3, 2017 Over the last few weeks, New Yorkers have watched with great anxiety as Texas, Florida and Puerto Rico, among many other places, were pummeled by massive hurricanes. Whenever we see storm destruction, memories of Sandy re-enter our consciousness; as does the question: Is New…