Author: Devin
-

5 Solutions the Public Advocate Should Deliver for New York City
This article was originally published on Gotham Gazette on May 8, 2019 The New York City Public Advocate is a poorly defined position that, over its 30 years of existence, has often been used to advance the political interests and status of career politicians. I’m running for Public Advocate because I want to do something very different…
-

SimCity Showed Us Brilliant Civic Tech Interfaces 30 Years Ago. We Should Build Them for Real Now
This article was originally published on Gotham Gazette on May 8, 2019 I was eight years old when I first encountered a computer game called SimCity. The general premise of the game was that you were the mayor of a virtual city, and you would use game money to create a place for communities of “Sims” to live.…
-

Breakthroughs in Open Aid Presented at National VOAD Conference, May 6th, 2019
I presented the following in Nashville, Tennessee on May 6th, 2019 PDF Download
-

Madrid Demonstrates Successful Civic Engagement. Let’s Pay Attention as We Launch New York City Commission
This article was originally published on Gotham Gazette on March 24, 2019 Madrid turns its residents’ collective passions and intelligence into tangible improvements to city life. New York should do the same. New Yorkers had until February 22 to apply to join the Civic Engagement Commission (CEC), a new entity that city voters approved last election to manage civic…
-
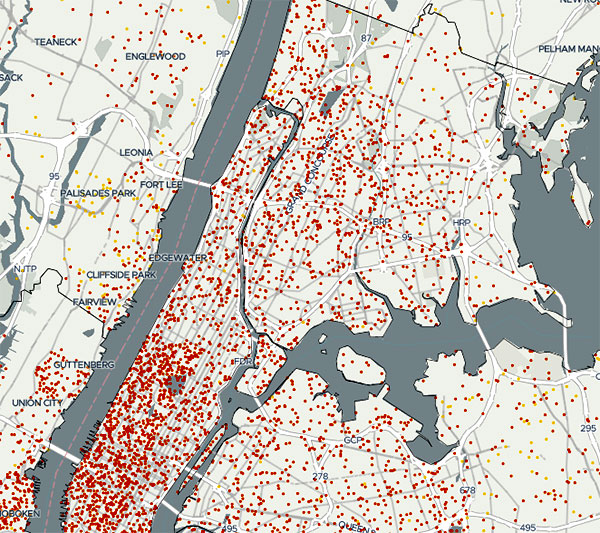
Moving Toward a Metro-Regional Approach to Planning and Advocacy
This article was originally published on Gotham Gazette on December 8, 2018 New York City and its neighbors have a problem. Unlike Los Angeles, Chicago, and the other major U.S. metropolitan areas that fit neatly within the standard city, county, and state political boundaries, our metropolitan area of over 22 million people does not. We’re…
-

New York City Shouldn’t Regulate Ride-Hailing Apps – It Should Compete With Them
This article was originally published on Gotham Gazette on November 30, 2018 Smartphones are transforming transit in cities all over the world, and city governments are struggling to figure out how to best manage the change. If the world was looking to New York City’s recently enacted legislation affecting for-hire vehicle companies, then there will be disappointment…
-

Anatomy of an Open Source Political Campaign at Open Camps Conference, 2018, New York City
I presented the following slides at the Open Camps Conference in New York City. PDF Download
-

Expanding Consul presented at MediaLab Prado, Madrid, Spain on November 15th, 2018
COLLECTIVE INTELLIGENCE FOR DEMOCRACY 2018 was a program of the MediaLab Prado in Madrid, Spain, funded by the Madrid City Government. I was lucky enough to be invited to participate in the two week program where I worked with a team to improve the Consul Participatory Democracy software platform. It was an extremely significant experience…
-

Mixing Tool Sets from Madrid and Taiwan to Improve Participatory Budgeting in New York presented at the g0v Summit 2018 in Taipei, Taiwan
“Mixing Tool Sets from Madrid and Taiwan to Improve Participatory Budgeting in New York: Leveraging Participatory Budgeting to Create a More Open and Participatory Government” was presented at the g0v (pronounced “gov zero”) Summit 2018 on October 6th, 2018 in Taipei, Taiwan. It was an ambitious presentation attempting to align the participatory democracy movements in…
-
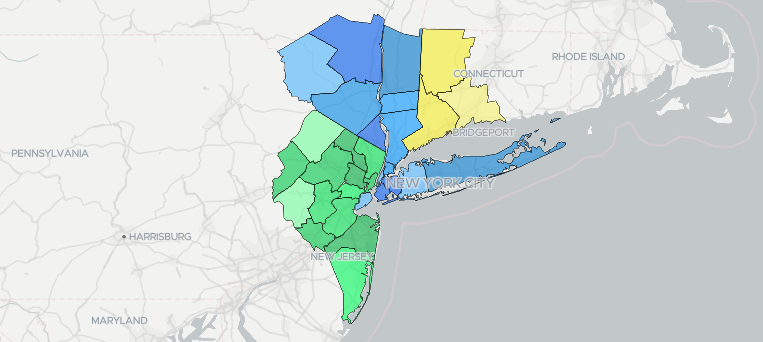
As City and State Politics Fail Us, Time to Rethink New York Metropolitan Area
This article originally appeared on Gotham Gazette on September 25, 2018 New York City is the world’s most popular city. We do lots of things exceptionally well here. But one thing we don’t do well is democracy. Voting rates within New York City are at historic lows, and corruption in Albany is at historic highs. Our politics…