Month: January 2016
-
Introducing Data Models for Human(itarian) Services
This was originally posted at Sarapis Immediately after a disaster, information managers collect information about who is doing what, where, and turn it into “3W Reports.” While some groups have custom software for collecting this information, the most popular software tool for this work is the spreadsheet. Indeed, the spreadsheet is still the “lingua franca”…
-
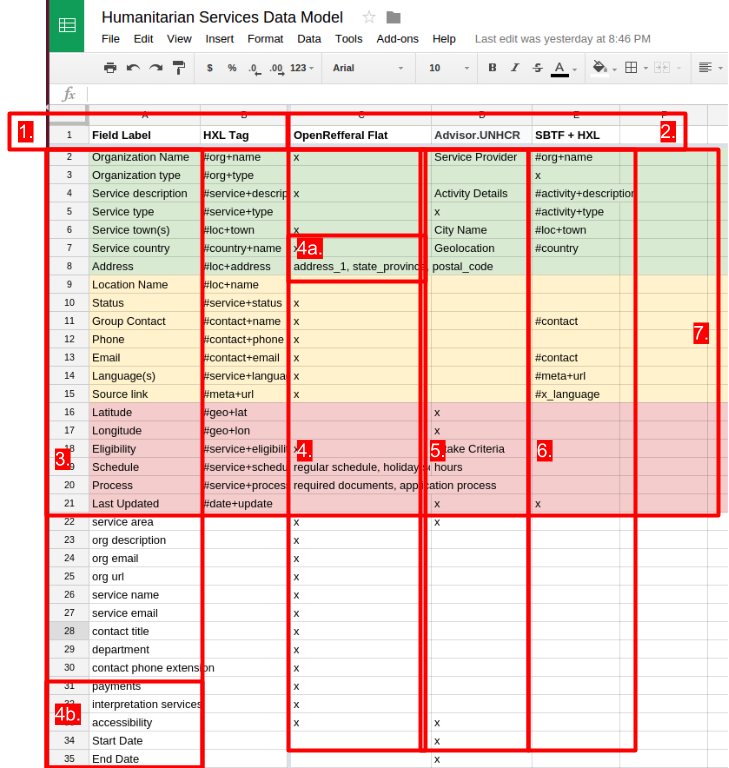
Creating a Shared Data Model with a Spreadsheet
Over the last year, a number of clients have tasked me with bringing datasets from many different sources together. It seems many people and groups want to work more closely with their peers to not only share and merge data resources, but to also work with them to arrive at a “shared data model” that they can…
-
The DIY Databases are Coming
“The software revolution has given people access to countless specialized apps, but there’s one fundamental tool that almost all apps use that still remains out of reach of most non-programmers — the database.” AirTable.com on CrunchBase Database technology is boring but immensely important. If you have ever been working on a spreadsheet and wanted to be…